- Published on
How to calculate a user's position in a DynamoDB ranking table
- Authors

- Name
- Tobias Geiselmann
- @geiselmann



For a recent project, I wanted to rewrite an existing application where user's can sign up for a running event, track the distances from their running activities and get an overall leaderboard, highest distance wins. Because I wanted to make this really performant and serverless applications make me sleep better at night, guess what I went with? The greatest database in the world, DynamoDB.
So I started modelling the data and listing all access patterns, but quickly ran into a problem. When the user logs in to the application and chooses an event he registered for, the application should display his absolute position for that event in the ranking table, something like "You are ranked 211th out of 1539". But I couldn't think of any efficient way to handle this access pattern in DynamoDB. After tinkering for a while, I decided to get some help from someone who should know if this is possible: @houlihan_rick and @alexbdebrie.

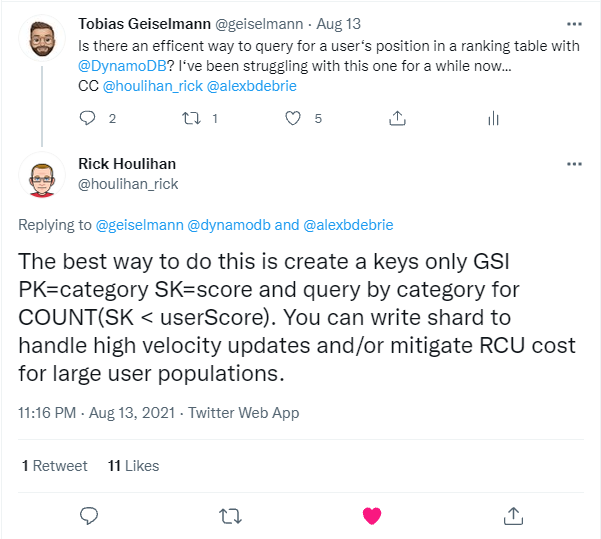
And of course it is possible. The idea is as simple as powerful. We create a global secondary index, where we use the Event ID as partition key and the total running distance as sort key. The nice thing with a GSI is that we can increase the sort key whenever a user tracks a new running activity. We can then calculate a user's absolute position by querying by the Event ID for all items that have a SK that is greater than the user's current distance. The count of these items plus one is the user's position.
DynamoDB enforces some limits that we should take into consideration here. There is a 1 MB limit on the size of an individual query request. Ideally, we do not want to be forced to make multiple requests to calculate a user's position. That's why @houlihan_rick proposed to use a keys only global secondary index, to keep the individual item size as small as possible.
A single item in the DynamoDB table would look like this (I've included the keys only):
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| USER#1 | EVENT#1 | EVENT#1 | 82.3 |
| USER#2 | EVENT#1 | EVENT#1 | 111.5 |
| USER#3 | EVENT#1 | EVENT#1 | 54.0 |
If we query for EVENT#1 by the global secondary index, we get closer to what we want:
| GSI1PK | GSI1SK | PK | SK |
|---|---|---|---|
| EVENT#1 | 111.5 | USER#2 | EVENT#1 |
| EVENT#1 | 82.3 | USER#1 | EVENT#1 |
| EVENT#1 | 54.0 | USER#3 | EVENT#1 |
Now we only need to count all items that are greater than the user's current distance and add one. You might be wondering why we are not simply using a "greater or equal than" comparison. Imagine the following case:
| GSI1PK | GSI1SK | PK | SK |
|---|---|---|---|
| EVENT#1 | 111.5 | USER#2 | EVENT#1 |
| EVENT#1 | 82.3 | USER#1 | EVENT#1 |
| EVENT#1 | 82.3 | USER#3 | EVENT#1 |
Both USER#1 and USER#3 have the same score. Which position are they at? Both second? Or both third? For my use case, I went with Standard competition or "1224" ranking. Therefore we count all items that have a score greater than the user's score and add one.
The implementation
Querying for the current position of a user is actually pretty simple:
result = client.query({
TableName: 'Ranking',
ScanIndexForward: false,
IndexName: 'GSI1',
KeyConditionExpression: 'GSI1PK = :event AND GSI1SK > :distance',
ExpressionAttributeValues: {
':event': 'EVENT#1',
':distance': 82.3,
},
Select: 'COUNT',
})
To make things event more efficient, we can set the Select attribute to COUNT. That way we don't receive the items itself, but rather the item count, which is all we want to know.
{
"Count": 1,
"ScannedCount": 1
}
If we add one, we see that USER#1 who has a current distance of 82.3 kilometers is on the second place!
Tracking a new distance is also pretty simple. All we have to do is update the user item and add the distance:
result = client.update({
TableName: 'Ranking',
Key: {
PK: 'USER#1',
SK: 'EVENT#1',
},
UpdateExpression: 'ADD GSI1SK :distance',
ExpressionAttributeValues: {
':distance': 11.2,
},
ConditionExpression: 'attribute_exists(PK)',
})
A little bit of math
Assuming an average total running distance of less than 1000 kilometers per user and IDs in UUIDv4 format, we get an average item size of 162 bytes. If we divide the 1MB limit mentioned above, we see that we can calculate the position in one request as long as we don't have more than 6,472 users per event. For that calculation, we would need 256 RCUs.
For my use cases, this is fine as I do not expect more than 3,000 users per event. The maximum number of users could however easily be increased by using smaller IDs. For even larger user populations, we could use write sharding as suggested by @houlihan_rick, but that's a topic for another post.